

一、常见深度学习工具库
PyTorch:Facebook主导的研究型框架,动态计算图特性突出
TensorFlow/Keras:Google开发的工业级框架,适合生产环境
ONNX
Transformers 库:HuggingFace 推出的自然语言处理专用框架
paddlepaddle:百度飞桨平台
二、pytorc介绍
1、PyTorch 教程
PyTorch 是一个开源的机器学习库,主要用于进行计算机视觉(CV)、自然语言处理(NLP)、语音识别等领域的研究和开发。
PyTorch由 Facebook 的人工智能研究团队开发,并在机器学习和深度学习社区中广泛使用。
PyTorch 以其灵活性和易用性而闻名,特别适合于深度学习研究和开发。
PyTorch 特性
动态计算图(Dynamic Computation Graphs): PyTorch 的计算图是动态的,这意味着它们在运行时构建,并且可以随时改变。这为实验和调试提供了极大的灵活性,因为开发者可以逐行执行代码,查看中间结果。
自动微分(Automatic Differentiation): PyTorch 的自动微分系统允许开发者轻松地计算梯度,这对于训练深度学习模型至关重要。它通过反向传播算法自动计算出损失函数对模型参数的梯度。
张量计算(Tensor Computation): PyTorch 提供了类似于 NumPy 的张量操作,这些操作可以在 CPU 和 GPU 上执行,从而加速计算过程。张量是 PyTorch 中的基本数据结构,用于存储和操作数据。
丰富的 API: PyTorch 提供了大量的预定义层、损失函数和优化算法,这些都是构建深度学习模型的常用组件。
多语言支持: PyTorch 虽然以 Python 为主要接口,但也提供了 C++ 接口,允许更底层的集成和控制。
模型定义与训练:PyTorch 提供了
torch.nn模块,允许用户通过继承nn.Module类来定义神经网络模型。使用forward函数指定前向传播,自动反向传播(通过autograd)和梯度计算也由 PyTorch 内部处理。神经网络模块(torch.nn):提供了常用的层(如线性层、卷积层、池化层等)。支持定义复杂的神经网络架构(包括多输入、多输出的网络)。兼容与优化器(如torch.optim)一起使用。GPU 加速:PyTorch 完全支持在 GPU 上运行,以加速深度学习模型的训练。通过简单的
.to(device)方法,用户可以将模型和张量转移到 GPU 上进行计算。PyTorch 支持多 GPU 训练,能够利用 NVIDIA CUDA 技术显著提高计算效率GPU 支持:自动选择 GPU 或 CPU。支持通过 CUDA 加速运算。支持多 GPU 并行计算(DataParallel或torch.distributed)。
2、安装教程
安装指南链接:🔗
3、结构说明
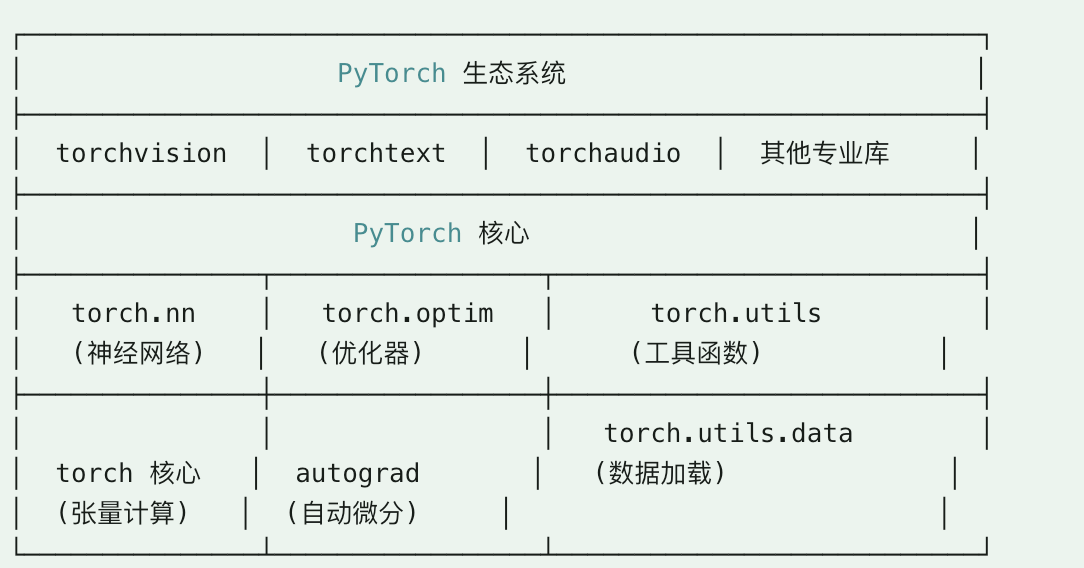
PyTorch 主要有以下几个基础概念:张量(Tensor)、自动求导(Autograd)、神经网络模块(nn.Module)、优化器(optim)等。
张量(Tensor):PyTorch 的核心数据结构,支持多维数组,并可以在 CPU 或 GPU 上进行加速计算。
自动求导(Autograd):PyTorch 提供了自动求导功能,可以轻松计算模型的梯度,便于进行反向传播和优化。
神经网络(nn.Module):PyTorch 提供了简单且强大的 API 来构建神经网络模型,可以方便地进行前向传播和模型定义。
优化器(Optimizers):使用优化器(如 Adam、SGD 等)来更新模型的参数,使得损失最小化。
设备(Device):可以将模型和张量移动到 GPU 上以加速计算。
PyTorch 架构图
训练模型(数据准备,构建模型(一个继承两个方法)、225原则)
训练模型是机器学习和深度学习中的核心过程,旨在通过大量数据学习模型参数,以便模型能够对新的、未见过的数据做出准确的预测。
训练模型通常包括以下几个步骤:
数据准备:
收集和处理数据,包括清洗、标准化和归一化。
将数据分为训练集、验证集和测试集。
定义模型:
选择/构建模型架构(如层数,神经元数量、激活函数),例如决策树、神经网络等。
初始化模型参数(权重和偏置)。
选择损失函数:
根据任务类型(如分类、回归)选择合适的损失函数。
# 定义损失函数(例如均方误差 MSE)criterion = nn.MSELoss()
选择优化器:
选择一个优化算法,如SGD、Adam等,来更新模型参数。
# 定义优化器(使用 Adam 优化器)optimizer = optim.Adam(model.parameters(), lr=0.001)
循环epochs
遍历数据集
前向传播:
在每次迭代中,将输入数据通过模型传递,计算预测输出。
output = model(x)
计算损失:
使用损失函数评估预测输出与真实标签之间的差异。
loss = criterion(output, Y)
梯度归零:
optimizer.zero_grad()
反向传播:
利用自动求导计算损失相对于模型参数的梯度。
loss.backward()
参数更新:
根据计算出的梯度和优化器的策略更新模型参数。
optimizer.step() # 更新参数
迭代优化:
重复步骤7-11,直到模型在验证集上的性能不再提升或达到预定的迭代次数。
评估和测试:
使用测试集评估模型的最终性能,确保模型没有过拟合。
模型调优:
根据模型在测试集上的表现进行调参,如改变学习率、增加正则化等。
部署模型:
将训练好的模型部署到生产环境中,用于实际的预测任务。
代码演示:
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 定义一个简单的神经网络模型
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(2, 2) # 输入层到隐藏层
self.fc2 = nn.Linear(2, 1) # 隐藏层到输出层
def forward(self, x):
x = torch.relu(self.fc1(x)) # ReLU 激活函数
x = self.fc2(x)
return x
# 2. 创建模型实例
model = SimpleNN()
# 3. 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam 优化器
# 4. 假设我们有训练数据 X 和 Y
X = torch.randn(10, 2) # 10 个样本,2 个特征
Y = torch.randn(10, 1) # 10 个目标值
# 5. 训练循环
for epoch in range(100): # 训练 100 轮
output = model(X) # 前向传播
loss = criterion(output, Y) # 计算损失
optimizer.zero_grad() # 清空之前的梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 每 10 轮输出一次损失
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/100], Loss: {loss.item():.4f}')
print("\n=== 保存完整模型 ===")
torch.save(model, 'full_model.pth')
# 保存状态字典----模型参数权重
state_dict = model.state_dict()4、用法
5、基于pytorch构建transformer
6、模型部署
7、模型保存和加载
参考链接
PyTorch 官网 :https://pytorch.org/
PyTorch 官方入门教程:https://pytorch.org/get-started/locally/
PyTorch 官方文档:https://pytorch.org/docs/stable/index.html
PyTorch 源代码:https://github.com/pytorch/pytorch
