1、前言
今天主要讲一讲rag系统的优化这块的内容,其实如果单从编码的角度来看构建一个rag实际上是一个相对来说比较简单和轻松的工作,无论说是基于现有的框架比如说UltraRAG、RAGgraph还是说组件库langchain亦或是说一些新兴的低代码平台Coze,Dify,n8n等等都可以轻松实现。但是实现一个稳定、可靠、准确的RAG系统其实才是最哪的。
2、难点
但是难点到底在哪里呢。其实本质上除了在系统稳定性和准确性上的外在表现外。难点是与RAG的构成模块所强相关的。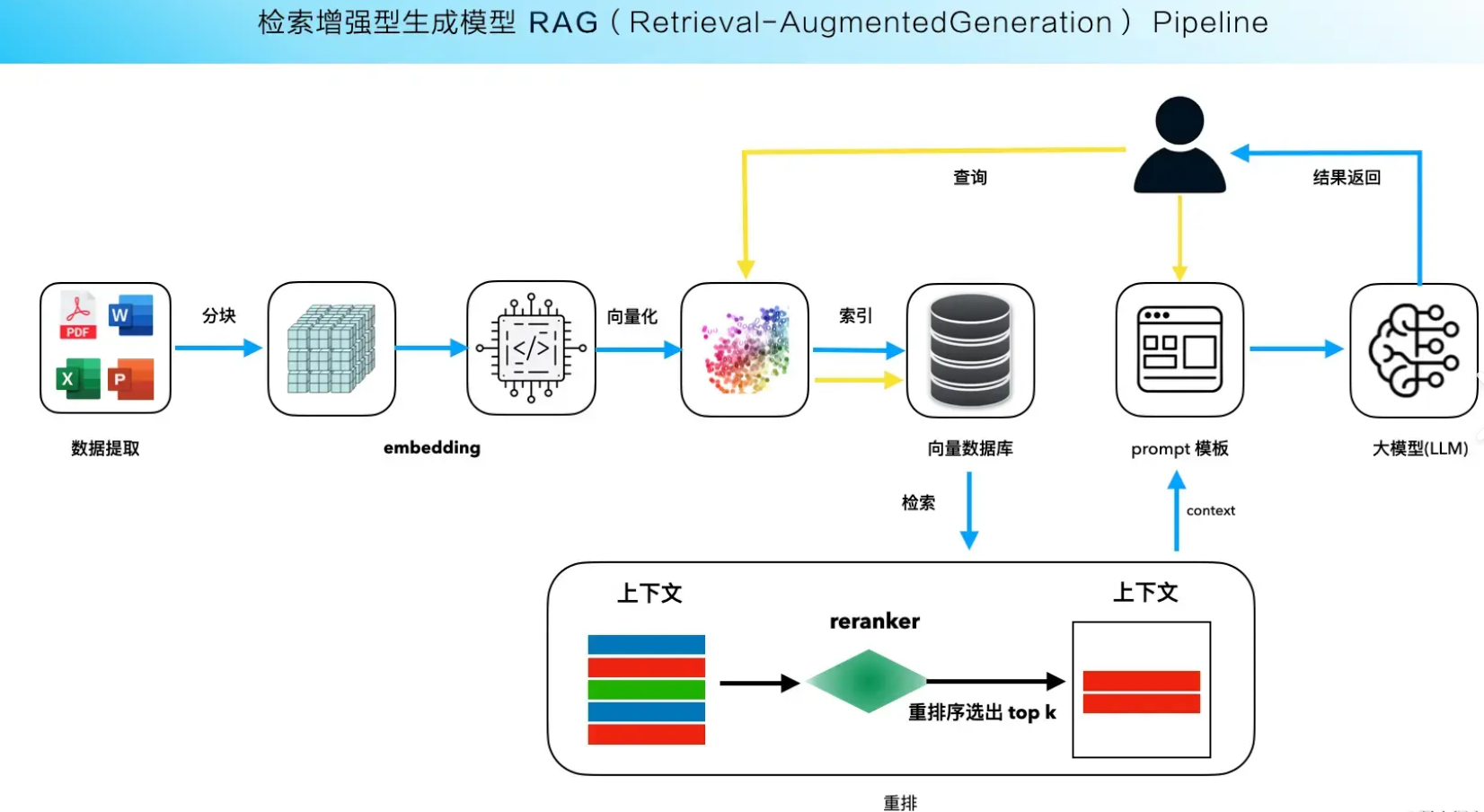 总而言之RAG的优化需要从数据处理,检索匹配,召回以及生成四个核心模块分别提升。下面比较全面的优化方向可以参考:
总而言之RAG的优化需要从数据处理,检索匹配,召回以及生成四个核心模块分别提升。下面比较全面的优化方向可以参考:
解决方向
📊 RAG 全链路优化点归总
核心模块 | 关键优化点 | 核心策略与选择 |
|---|
1. 数据处理 | 数据清洗 | 去无关字符、标准化格式、纠正错别字、去重。 |
| 分块策略 | 按固定长度、按句/段、按标记符、递归分块、滑动窗口。核心:避免语义割裂,匹配查询粒度。 |
| 元数据处理 | 提取并存储标题、来源、日期、章节等,用于后置过滤和增强Prompt。 |
2. 检索 | Embedding模型 | 选型:通用模型(text-embedding-ada-002) vs. 领域微调模型。核心:模型与任务的相关性。 |
| 向量维度 | 通常由所选模型固定(如384、768、1536维)。确保与向量数据库兼容。 |
| 向量数据库 | 选型:Pinecone, Weaviate, Qdrant, Milvus, PGVector。考量:性能、成本、过滤能力、托管服务。 |
| 索引策略 | HNSW(快、内存大) vs. IVF(平衡) vs. Flat(准、慢)。根据数据规模和查询延迟选择。 |
| 检索策略 | 纯向量检索 vs. 混合检索(向量+关键词如BM25)。后者可缓解术语不匹配问题。 |
3. 召回 | 召回数量 (Top-K) | 初始召回数K:设置一个较大的值(如20),为重排序提供充足候选。需平衡召回率与噪声。 |
| Reranker模型 | 选型:交叉编码器(如bge-reranker)比双编码器更精准。考量:速度与精度的权衡。 |
| 混合检索得分归一化 | 方法:Min-Max, Z-Score, 或分数融合(如RRF)。确保不同检索系统的分数可比。 |
| 重排参数设定 | 最终返回数量:在重排后,选择Top-N(如3-5个)最相关片段输入LLM。 |
4. 生成 | Prompt工程 | 指令设计:明确要求“基于上下文”,设定回答格式,处理“未知”。上下文编排:合理安排片段顺序与分隔符。以及COT的Prompt设计 |


