

本文章主要介绍RAG这一概念并介绍其来源,作用,简单实现流程,后续复杂的实现框架和架构会由后续文章讲解,本文不做描述,仅做入门讲解。
📜 一、来源:RAG 的诞生背景
RAG 并非凭空出现,它是为了解决大语言模型(LLM)的 “知识困境” 而诞生的。因为对于传统的LLM或企业来说存在能力边界问题、幻觉、LLM信息时效问题、企业信息保密需求等等。主要体现在下面:
RAG 的核心理念 在2020年左右由 Meta(Facebook)等机构的研究者明确提出:与其巨资重新训练或微调LLM本身,不如将LLM视为一个强大的“通用处理器”,通过外接一个“即时知识库”来动态地、按需地为它提供准确、最新的信息。 这一范式彻底改变了我们利用LLM的方式。
🎯 二、含义:什么是 RAG?
RAG 的全称是 检索增强生成。
检索:从海量、动态更新的外部知识库中,主动查找与当前问题最相关的信息片段。
增强:将检索到的信息作为 “上下文” 或 “参考依据”,插入到给LLM的指令(Prompt)中。
生成:LLM 基于提供的上下文,生成更准确、更可信、更具时效性的回答。
核心类比:
想象一个学识渊博但记忆停留在去年的教授(LLM)。现在,他身边配备了一位顶级的研究助理(检索系统)。每次学生提问,助理会立刻从最新的图书馆(外部知识库)中找出最相关的几页资料,放在教授面前。教授快速浏览这些资料后,再结合自己广博的学识,给出一个既专业又紧跟时代的回答。RAG 就是这位“研究助理”与“教授”协同工作的系统范式。
✨ 三、作用与优势:为什么需要 RAG?
RAG 的作用直接针对LLM的缺陷,带来了以下核心优势:
🧩 四、简单构成:一个最简 RAG 系统是如何工作的?
一个最基础的 RAG 系统通常由两个阶段、四个核心组件构成,形成一条清晰的工作流:
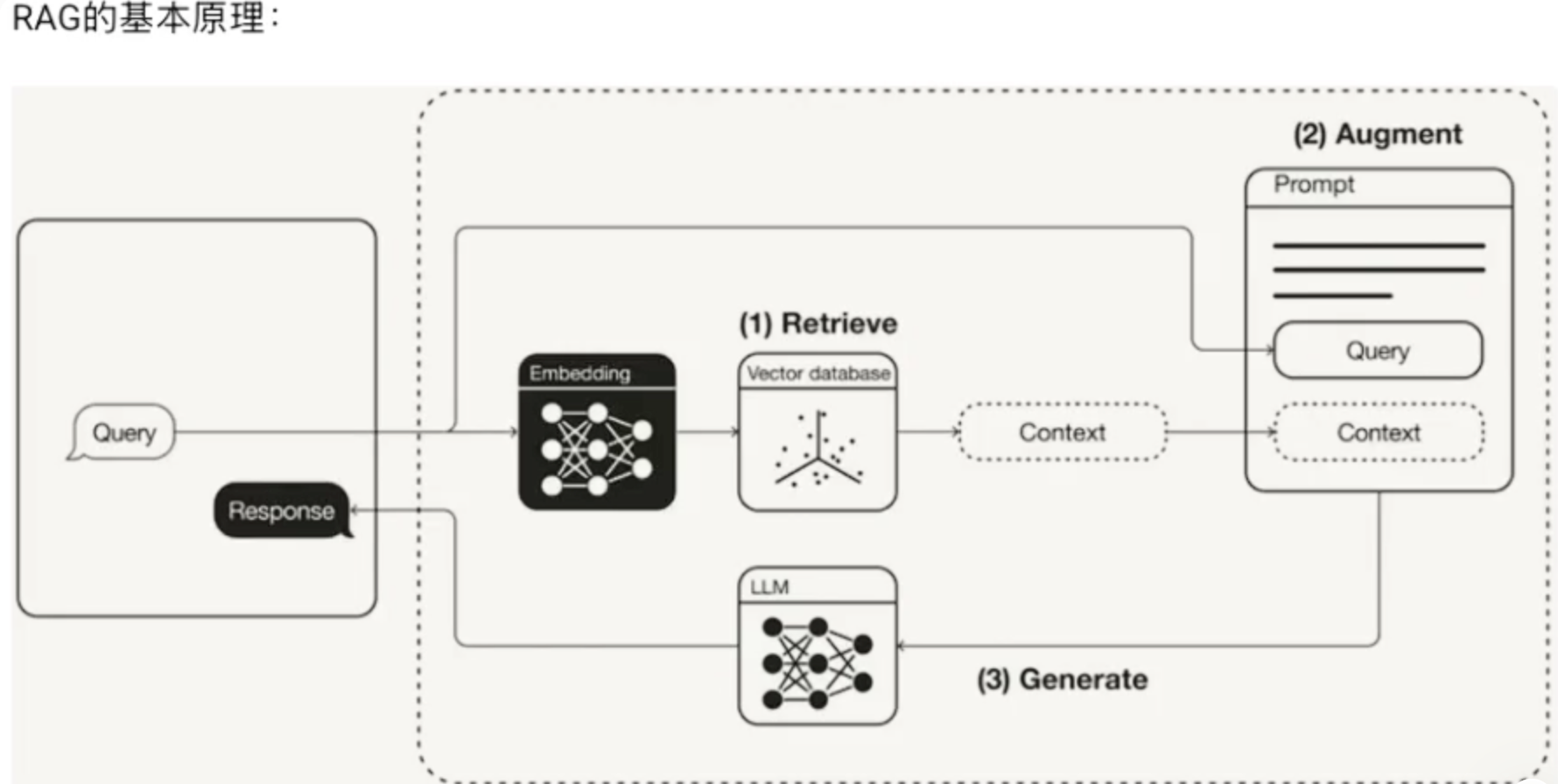
数据处理(对应索引阶段)
组件:文档加载器、文本分割器、嵌入模型。
输入:原始文档(PDF, Word, 网页等)。
输出:存入向量数据库的“文本片段-向量”对。
检索(对应问答阶段的第一步)
组件:检索器(通常与嵌入模型共享)。
输入:用户查询。
输出:从向量数据库中找出的Top-K个相关文本片段。
召回(对应问答阶段的中间处理)
组件:提示词模板。
输入:用户查询 + 检索到的文本片段。
输出:一个精心构建的、给LLM的完整提示(Prompt),其中明确指示LLM基于给定片段回答问题。
生成(对应问答阶段的最后一步)
组件:大语言模型。
输入:构建好的提示。
输出:最终的、增强后的答案。
一句话总结:RAG 通过 “检索-增强-生成” 的范式,将LLM的强大生成能力与外部知识库的准确性和时效性相结合,生成了更可靠、可追溯的智能答案。它已成为构建企业级、知识密集型AI应用的事实标准架构。
