

一、agent介绍
1、含义
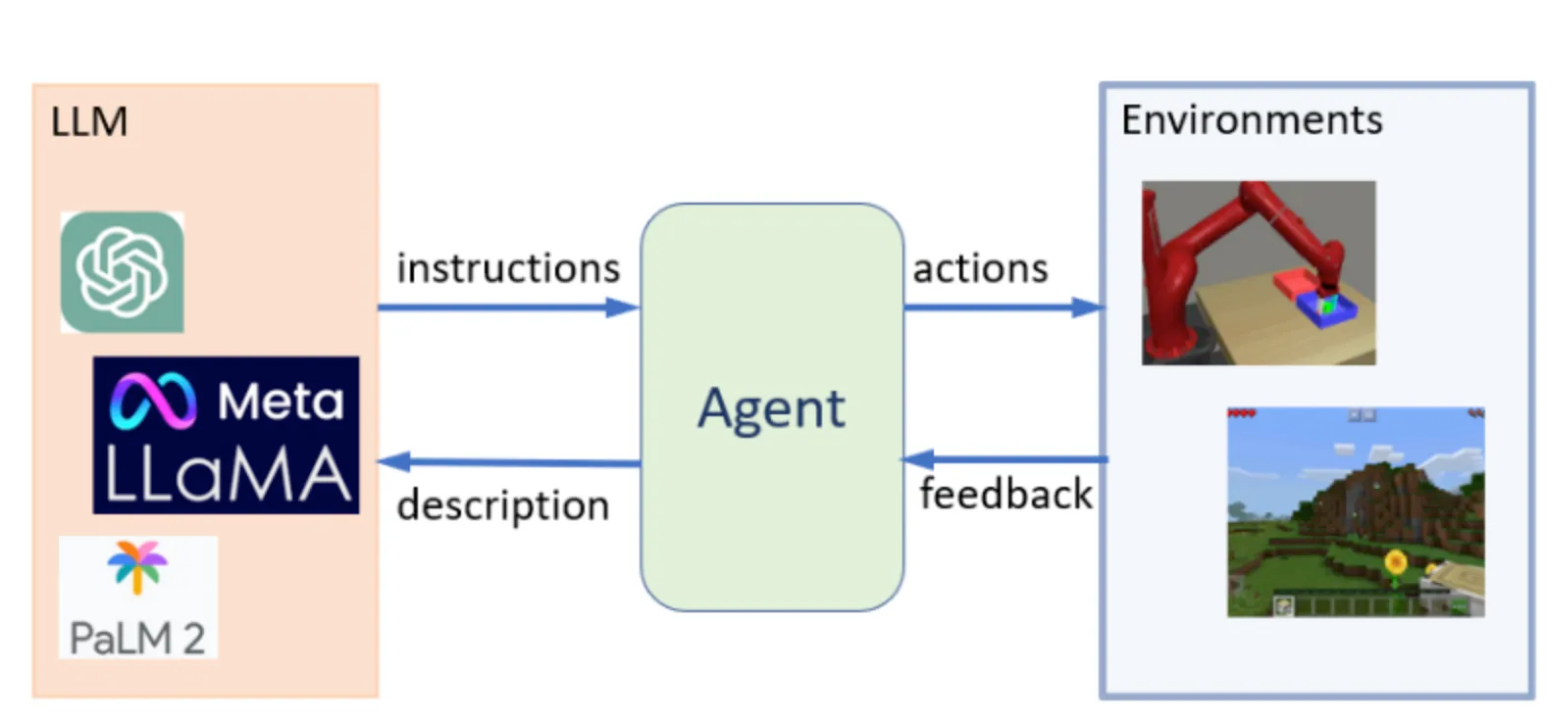
大模型 Agent 是以大语言模型为大脑,配合规划、记忆、工具调用等模块,能够自主完成复杂任务的系统。
它和传统 A 最大的区别在于:传统 AI 是你问一句它答一句,Agent 是你给它一个目标,它自己拆任务、调工具、一步步干完。具体差异可以从这几个维度来看:
1)目标导向 vs被动响应。传统大模型就是个对话机器,用户输入什么它输出什么,没有主动性。Agent 不一样,你给它个最终目标,比如"帮我调研竞品并写一份分析报告",它会自己规划要做哪些步骤、先做什么后做什么,然后一步步执行。
2)有记忆 vs 无状态。传统模型只能看到当前对话的上下文窗口,聊完就忘。Agent 有专门的记忆模块,短期记忆存当前任务的中间状态,长期记忆存历史经验,下次碰到类似问题可以复用。
3)能调用工具 vs 只能说话。传统模型只能输出文本,想搜索、算数、操作数据库都得人来做。Agent 能调用搜索引擎、执行代码、读写文件、调 AP!,真正把事情做出来。
4)多步推理 vs 单轮问答。Agent 能在执行过程中不断评估结果、发现问题、调整策略,形成一个闭环。传统 A 系统要么靠写死的规则引擎,要么就是一锤子买卖。
二、Agent 的核心架构
1、核心组件
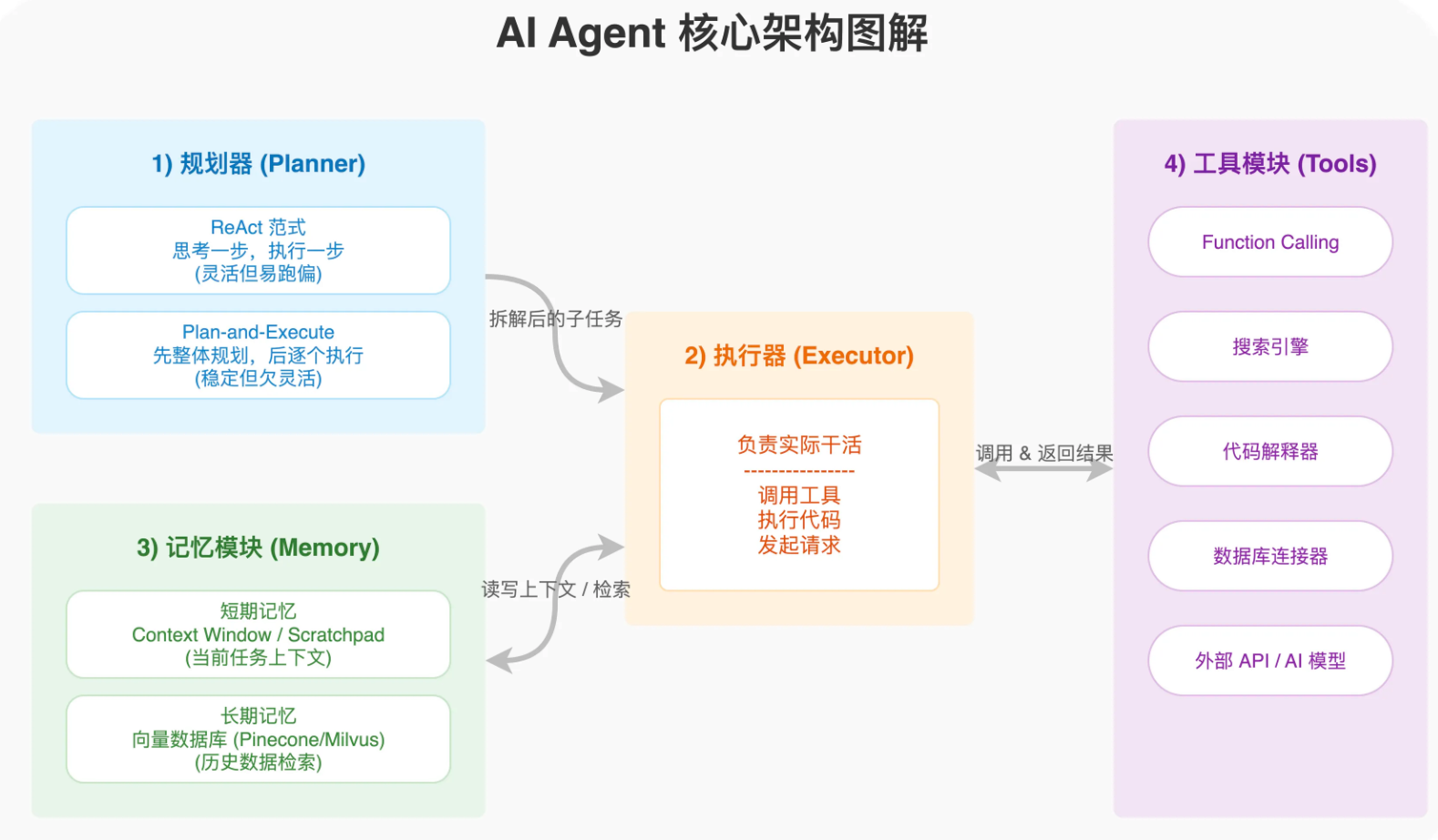
LLM Agent 的核心架构由四个部分组成:**LLM 核心、规划模块、记忆模块、工具模块**
1)规划器(planning)负责把复杂目标拆解成可执行的子任务。常见的规划方法有 ReAct 范式和 Plan-and-Execute 范式。ReAct 是思考一步执行一步,灵活但容易跑偏;Plan-and-Execute 是先整体规划再逐个执行,稳定但不够灵活。
2)执行器(LLM)负责实际干活,调用工具、执行代码、发起请求。
3)记忆模块(memory)分短期和长期。短期记忆通常就是当前任务的上下文,用 Context Window 或者 Scratchpad 实现。长期记忆-般用向量数据库存储,比如 Pinecone、Milvus、Chroma,需要的时候检索出来。
4)工具模块(tool)是 Agent 能力的关键扩展点。OpenAl 的 Function Caling、LangChain 的 Tools、AutoGPT 的 Plugins 都是这个思路。工具可以是搜索引擎、计算器、代码解释器、数据库连接器,甚至是另一个 AI 模型。
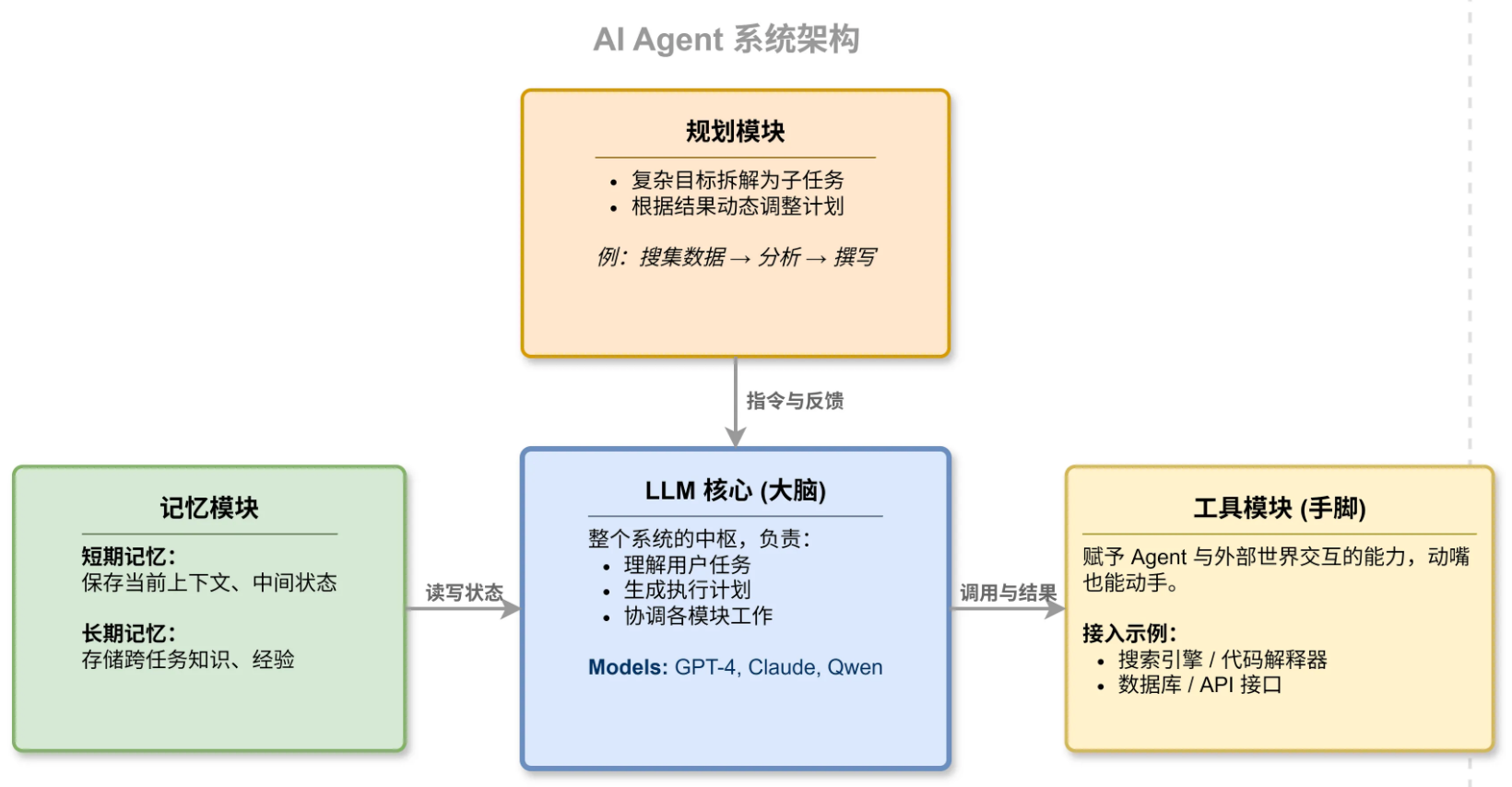
1)LLM 核心是整个系统的大脑,负责理解任务、生成计划、协调各模块工作。GPT、Claude、Qwen 这些大模型都可以充当这个角色。
2)规划模块负责把复杂目标拆成可执行的子任务。比如"帮我写一篇市场分析报告"这种任务,规划模块会拆成:搜集行业数据、分析竞品、整理趋势、撰写报告等步骤。执行过程中还能根据结果动态调整计划。
3)记忆模块分短期和长期两种。短期记忆保存当前任务的上下文和中间状态,长期记忆存储跨任务的知识和经验。没有记忆模块,Agent 千完上一步就忘了,没法处理多轮复杂任务
4)工具模块是 Agent 的手和脚、让它能和外部世界交互。搜索引擎、代码解释器、数据库、AP! 接口都可以作为工具接入没有工具,Agent 只能动嘴不能动手。
2、扩展知识
1、规划模块的实现细节
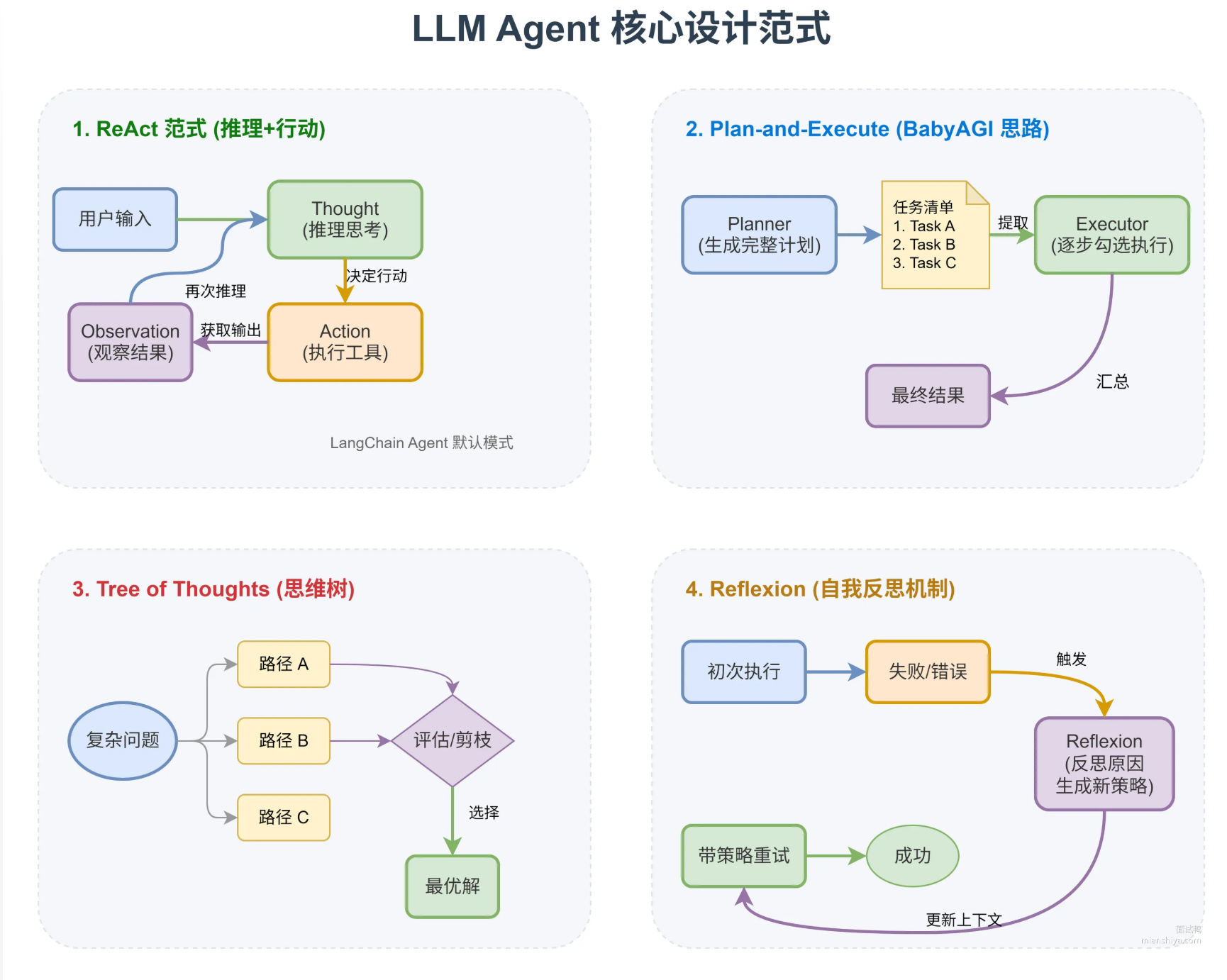
规划是 Agent 区别于普通 LLM 的关键能力。目前主流的规划方法有几种:
1)ReAct 范式把推理和行动交替进行。先 Thought 说明要做什么、为什么,再 Action 执行具体操作,然后 Observation 观察结果,循环往复。LangChain 的 Agent 默认就是这种模式。
2)Plan-and-Execute 范式先一次性生成完整计划,再逐步执行。BabyAG! 就是这个思路,先列出任务清单,一个个勾掉
3)Tree of Thoughts 把推理过程展开成树状结构、每步可能有多个分支,最后选最优路径。适合需要多步推理的复杂问题。
4)Reflexion 机制让 Agent 在失败后能反思原因、调整策略。不是简单重试,是带着教训重来。
2、记忆模块的工程实现
短期记忆最简单的做法是把对话历史拼进 Prompt,但会撞上下文窗口的墙。GPT-4Turbo 支持 128K Token,Claude3支持 200K,看着不少,但复杂任务一跑很快就满了更好的做法是用 Scratchpad,把关键信息结构化存储,只在需要时取用。MemGPT 这个项目就是专门做这个的,模拟操作系统的虚拟内存机制,让 Agent 能管理远超上下文窗口的信息量。长期记忆一般用向量数据库实现,常用的有:
3、工具模块的设计模式
工具调用是 Agent 能力扩展的关键。OpenA! 推出的 Function Caling,让模型能以结构化方式调用外部函数,一下子把工具集成的门槛拉低了。
工具设计有几个要点:
1)工具描述要清晰。模型是靠工具的文字描述来决定什么时候用、怎么用的,描述写得不好,模型就不会正确调用
2)参数 Schema 要严格。用 JSON Schema 定义参数类型和约束,模型生成的参数才能被正确解析。
3)工具粒度要合适。太粗的工具不够灵活,太细的工具选择困难。比如"搜索"这个工具,可以拆成"网页搜索"、"学术搜索"、"代码搜索",但别拆成"搜索标题"、"搜索摘要"这么细。
4)做好错误处理。工具调用失败是常态,要让 Agent 能识别失败、理解原因、决定是重试还是换方案。
各模块的协作流程
个完整的任务执行流程是这样的:
1)用户输入任务目标
2)LLM 核心理解任务,调用规划模块生成执行计划
3)按计划逐步执行,每步可能需要调用工具
4)执行结果存入短期记忆,重要经验写入长期记忆
5)LLM 核心评估进度,决定继续执行还是调整计划
6)任务完成,汇总结果返回给用户
这个循环可能要跑很多轮。AutoGPT 处理一个复杂任务,经常要调几十次 LLM、十几次工具,整个过程可能花好几分钟。
三、面试官追问
提问:Agent 的规划模块怎么处理计划执行失败的情况?
回答:主要有三种策略。一是重试,简单粗暴但对瞬时故障有效。二是回退重规划,把失败的步骤和原因反馈给规划模块,重新生成后续计划。三是引入 Reflexion 机制,让 Agent 分析失败原因、总结教训,然后带着新认知重新尝试。实际项目中-般组合使用,先重试 2-3 次,不行就触发重规划,重要任务还会存下失败案例供后续学习。
提问:记忆模块用向量数据库存储时,怎么决定存什么、什么时候存、存多久?回答:存什么主要看信息的重要程度和复用价值,任务的最终结果、关键决策点、失败教训这些值得存。什么时候存一般是任务完成时批量写入,也可以设置國值触发增量存储。存多久需要淘汰策略,常见的有按时间淘汰、按访问频率淘汰、按相关度评分淘汰。还要考虑去重和压缩,相似的记忆合并成一条,节省存储也减少检索噪声。
提问:工具太多的时候模型选错工具怎么办?
回答:首先是减少候选工具数量,不要一股脑全塞进去,根据当前任务类型动态筛选相关工具。然后是优化工具描述,写清楚每个工具的用途、适用场景、参数含义,让模型能准确判断。还可以加一层工具路由,先用一个轻量模型或规则引擎粗筛,再让主模型在小范围内精选。最后是加校验环节,工具调用前检查参数合法性,调用后验证结果是否合理,不合理就让模型重新选择
提问:ReAct 和 Plan-and-Execute 两种 Agent 范式有什么区别?实际项目中怎么选?
回答:ReAct 是边想边做,每一步先推理要做什么、为什么,然后执行,看到结果再决定下一步。优点是灵活,能根据中间结果随时调整;缺点是容易跑偏,任务一复杂就会丢失方向。Plan-and-Execute 是先整体规划出完整的步骤列表,再逐个执行。优点是稳定,不容易偏离目标;缺点是不够灵活,如果中间某步失败需要重新规划。实际选择看任务特点:探索性强、结果不确定的用 ReAct;目标明确、步骤可预期的用 Plan-and-Execute;复杂任务可以混用,外层 Plan-and-Execute 保证方向,内层 ReAct 处理细节。
提问:Agent 的记忆模块怎么设计?长期记忆和短期记忆分别用什么技术实现?
回答:短期记忆最简单的做法就是把对话历史和中间结果拼到 Promot 里,受限于模型的上下文窗口。更好的做法是用Scratchpad,把关键信息结构化存储,只在需要时取出来。长期记忆一般用向量数据库、把历史经验、知识片段 Embedding之后存进去,检索时算相似度取 Top-K。常用的向量库有 Pinecone、Milivus、Chroma、Weaviate。设计上要注意记忆的增删改查策略,不能无限堆积,需要定期压缩或淘汰不重要的内容。
提问:怎么解决 Agent 多步执行时的错误累积问题?
回答:几个常见的思路:一是加强单步准确率,用更强的模型、更好的 Prompt、更精准的工具;二是加检查点,每步执行完校验结果是否合理,不合理就重试或回退;三是引入自我反思机制,让 Agent 定期回顾执行历史,发现偏离目标就及时纠正;四是限制自主性,关键操作要人工确认,不让 Agent 完全自动跑。实际生产中这几种方法一般组合使用。
